




![]()
![]()
![]()
BibTeX | RIS | EndNote | Medlars | ProCite | Reference Manager | RefWorks
Send citation to:
URL: http://ijmm.ir/article-1-1341-en.html



2- Department of Information Science, Faculty of Psychology and Educational Sciences, Kharazmi University, Tehran, Iran
3- Department of Information Science, Faculty of Management, University of Tehran, Tehran, Iran ,
Archives, dating back to the calligraphy creation, have undergone many changes over time in terms of concept, importance, types, and application between different languages and culture (1). So that in the twelfth century the archives found a new concept, and became repositories where valuable documents are kept for future use (2). In other words, archives, which created and expanded as a result of organizations, or individual activities, are systematic collections of non-current records and documents that have been received or organized in conjunction with the organization, entity or individual activities, and are kept because of their permanent value (3, 4). The archive's mission is to collect, protect and organize all kinds of records with scientific methods and to provide effective services to different users based on legal rules and regulations (5).
Meanwhile, throughout history, there have been different types of archives from different aspect; it is sometimes used as a "Medical filing" to effectively save a variety of medical records. Medical archives often cover various issues and materials, including data, information, documents, and literature related to health care, research, and education (6). Also, health records and documents as one form of medical archives, as an important legal document for the exercise of human rights has played an important role in history and is the basis for fulfilling individual rights, both in social and legal interactions and enforce privacy laws and determine the health status of people in the community (7). On the other hand, the importance of medical records to provide health services and to conduct much related research is undeniable, undoubtedly medical professionals need information and records about the previous diagnosis, therapies, prescriptions, and drugs to keep track of the treatments and their results. In other words, researchers believe that contemporary digital health records contain a large amount of data such as patient records, physician notes, and copy in text format and its contents can lead to improved healthcare quality, fewer medical errors, and cost reduction.
However, dysfunctional management of records, information and medical records that are the most important patients health database, exposes the health system to a multitude of incomplete or missing files. This causes a disturbance in the process of retrieving documents and the result is the lack of proper healthcare services in the health system or occurrence of medical errors that will undoubtedly have irreversible consequences. Also in the information technology epoch, medical archives and records are considered the most important, richest and truest source of medical and health information. Because it is based on the medical science facts and with scientific optimization of medical records according to national and international rules and standards and employing scientific methods of storage, protection and maintenance and accurate health information restoration, a great change in the health information system in educational and research affairs occurs (8).
Unfortunately, although the importance of records and the necessity of creating a medical archive, not enough attention has been paid to this field from various perspectives, so that effective and efficient systems for storing, organizing and indexing, retrieval, and tracking of records are not available; It is clear that this mismanagement leads to many disorders and problems in the health system and especially for the patients. Maturity, dynamic, and intellectualism of various scientific disciplines can be measured according to their research activities. The manifestation of these activities may be in different ways, which vary according to the area or field of science and its necessities. Scientometrics draws a knowledge map through processing, extraction, and sorting of information and it allows analysis, routing, and display of knowledge; In addition, this field moves to ease access to information, reveal knowledge structures and assist knowledge seekers to achieve successful outcomes (9).
One of the most widely used methods for drawing and analyzing the structure of knowledge in different domains is the co-occurrence of words or in other words, the relationship between the words used in different parts of documents; this method, introduced in the 1980 s, is based on the assumption that using key vocabulary in the title, abstract, keywords and text of academic productions indicate the proximity of concepts to each other through which structure, concepts, and elements of a scientific field are determined. In this analysis, indicators are used for the co-occurrence of two items - such as the proximity and similarity index, which is used to measure the relationship between items.
Based on these indicators, in this approach, we draw the of domains and scientific fields (10), identify hidden and prominent patterns, determine the internal and external relations of concepts (11), detection of emerging events, determination of hierarchical relationships of concepts in the ontology of scientific domains and fields of specialized knowledge, clustering the concepts of scientific fields, and science and knowledge policy- making (12). The main feature of the co-word analysis is to visualize the logical structure of a particular field by drawing a concept map.
On the other hand, in information retrieval, we must classify the retrieved documents based on a subject similarity that is referred to as evidence clustering. To do so, each document can be compared with other documents in pairs, and the number of common subjects can be obtained. This is determining the number of subjects that have occurred in both evidences compared to common (13). Clustering tries split the data into clusters that maximize the similarity between data within each cluster and minimize the similarity between data within different clusters (14). Cluster analysis seeks to organize a set of data into a series of clusters so that the data in each cluster have the highest degree of similarity and the data belonging to different clusters have the maximum degree of dissimilarity. Some nodes in the graph tend to be in a cluster. In other words, the number of links connected between neighbors of a node is called the total number of possible links is called the impact of clustering effect. As a result, after clustering, an expert must interpret the clusters created, and in some cases, it is necessary to remove some of the parameters that are considered in clustering but are irrelevant or not very important, and clustering should be done from the beginning (15).
Thus, co-word analysis as one of the common methods in studies of science gauging revealed thematic clusters under a field of research, considers its conceptual and semantic relationships and outlines the intellectual structure of knowledge in the field under study to provide valuable assistance for interested researchers. Accordingly, due to the instability of medical archives in the health system and the necessity of establishing medical archives, and the importance of their protection and maintenance, the present study intends to evaluate the role of these archives in related research regarding the use of medical archives in promotion of the health system. In the following, we review some researches in the field of medicine which have been performed using approaches such as scientometrics and co-occurrence of words.
In 2017, Vaziri studied the status of systematic review articles in the field of medical sciences in Iran from 1970 to 2016 on the Web of Science website based on scientometric indicators. The results showed that the world review articles have grown more compared with other scientific products and researchers from the United States, the United Kingdom and Canada have contributed more than 60% in the production of review articles and Iranian researchers produced only one percent of the review articles in this field (16).
In 2018, Baji et al. mapped the intellectual structure of health literacy based on lexical analysis on the Web of Science database from 1993 to 2017. The results showed that the clustering coefficient (7.01) and network density (0.58) were high in this field. Also, the intellectual structure of this area consists of eight thematic clusters. The areas of health care, psychiatry and psychology, public health, social sciences, communications, health services, and health education have the highest centrality across the network. The results of this study showed that the mental structure of health literacy is a continuous structure with proper communication between concepts and its constituent subjects which represents the main essence and consistency of this area, and as a branch of medical science, it has managed to establish coherent and consistent relationships with the fields of social and human sciences (17).
In another article in medical and laboratory equipment fields, Emami, Riahinia, and Soheili (2018) also analyzed the co-occurrence words of patents in the field of medical and laboratory equipment from 1984 to 2014 at the US Patent and Trademark Office database. Findings showed that in terms of frequency, the keywords "menstrual fluid" and in terms of co-occurrence, the two keywords "menstrual fluid - magnetic resonance imaging equipment" had the highest frequency. Hierarchical clustering by the "Ward" method led to the formation of eight clusters of general equipment, rehabilitation equipment, dental equipment, medical equipment, emergency equipment, laboratory equipment, diagnostic equipment and medical supplies. The results indicate that co-word maps have shown changes and stability in concepts and terms related to this scientific field (18).
In research conducted in 2019, Saheb examined the structure of scientific networks in the field of health information using a data-mining method and bibliometric research method. In this area, 30115 articles from the science database belonging to the years 1974 to 2018 were reviewed. This study showed that the three main issues were the use of computer science in health care, the impact of health information on patient safety and the quality of health care, and decision support systems. Also, since 2016, health information has entered a new era to provide predictive, preventive, personal and participatory health systems. The study revealed that future research fields may examine generated health data, deep learning algorithms, tutorial tools and decision support systems on the Internet [19].
In 2020, Barrera-Cruz et al. In their bibliometric research reviewed the Medical Archives journal from 1970 on the WOS database. Over the years, a total of 4334 scientific papers have been published, averaging 87 papers per year, of which 78% are research papers, 7% review papers, 9% conference papers, 3% letter to the editor, 1% editorial and 2% Other categories (notes, error, short review). A total of 50,645 citations were received in half a century. The scientific focus of the journal has evolved with chronic epidemiological changes in morbid disease, transmission of parasitic infectious diseases such as embases and its complications to chronic institutions, respectively. In the last five years, half of the published articles are related to cancer, cardiovascular, neurological and renal diseases, diabetes and obesity (20). In a 2020 study, Hu et al. provided a broad overview of data mining methods in medicine through illustration and bibliography by analyzing authors, journals, institutions, and countries while providing a reference for researchers. In this study, a knowledge map was drawn by Citespace and VOSviewer information illustration software based on theoretical literature retrieved from WOS from 2011 to 2019. Based on the results, the annual number of published and cited articles has gradually increased over the past decades, indicating a growing interest in medical information data mining research in response to the need to discover medical knowledge, assist physicians, improve health General and patient support (21).
In 2021, Chintalapudi et al. conducted a study entitled "Text Mining and Emotional Analysis of Sailors' Medical Documents" to a better perception of seafarer's medical problems. More than 3,000 sailors were studied in the study between 2018 and 2020, and three-year records of patients were extracted to understand patients ' perspectives and experiences through text mining and emotional analysis and text mining methods were used to analyze medical records and to examine common injuries that occurred on the deck of a ship (22).
The literature review indicates that the use of scientometrics approach and co-occurrence of words in medical fields including the fields related to medical archive is common and has numerous achievements, but so far, no independent research has been done on the use of co-occurrence of words in research related to medical archives. Thus, the present study aims to investigate the role and use of medical and health archives in scientific research based on research topics indexed in web of science to answer the following questions:
- What is the status of research related to medical archives in terms of the production process, research medium, language, countries, participating institutions and researchers, participating and citing research areas, keywords and journals?
- What is the hierarchical clustering of research topics related to medical archives based on co-occurrence analysis?
What is the status of clusters derived from co-occurrence analysis in terms of maturity and development in the strategic chart in the field of medical archives?
The present study is a descriptive study that was done with a scientometric approach and using the method of synonym analysis and hierarchical clustering technique and strategic diagram. The statistical population of this study consists of all published researches related to the medical archive. To retrieve the relevant records, different combinations and names of medical archives were identified with the help of a thesaurus and identified and retrieved using Boolean operators and truncation and phrase search in the form of the following search strategy.
(TS="medic* archiv*") OR (TS="health* archiv*") OR (TS="archiv* medic*") OR (TS="archiv* health*") OR (TS="archiv* of medic*") OR (TS="archiv* of health*")
It should be noted that by creating a thesaurus in Excel, the keywords were controlled, edited and standardized, and similar, identical, analogous keywords and plural and singular forms of integration and non-specialized keywords were removed. Hierarchical clustering is usually used to perform homologous lexical analysis. Hierarchical clustering can identify clusters related to each keyword and show the relationship between them. For this reason, hierarchical clustering was performed using SPSS software. In the hierarchical clustering method, like a tree, each smaller branch is part of a larger branch, and finally, all of them are connected hierarchically to the trunk of that tree. The result of the hierarchical clustering that can be seen in Figure 1 may be considered as follows that objects in the form of a tree diagram are recursively grouped into smaller and smaller clusters, which is the so-called dendrogram. In this diagram, the horizontal axis represents the data points and the vertical axis represents the similarity between the data points.

Figure 1. Calculating the ability of biofilm formation compared to the control
The advantage of hierarchical clustering is that through which we can find a hierarchical relationship between objects and it is easier to see the similarity between objects visually. In other words, in a tree diagram, the less the mouth depth of the two objects is, the intensity of the similarity can be easily understood (13). The other advantage of the hierarchical clustering method is that the number of clusters must not be determined in advance. Whereas in other methods, the number of clusters must be known in advance. But the decision to fragmentize the extent and the number of clusters is controversial. In the hierarchical method, clusters are created in two main ways: the density approach and the splitting approach. In the density approach, each object or data is considered to be a cluster, and gradually these smaller clusters are merged so that all objects are in a cluster. Sometimes this does not happen until this stage and only until it reaches the desired number of clusters. Clustering with this approach is possible in several ways, one of which is the ward method and where the average distance of objects in a cluster is first calculated and then, like the Variance calculation method, the difference between the distance of each object and that mean is measured. In other words, the ward method is based on the sum of squares of each data from one cluster with the mean vector of that cluster. This concept can be represented as the following formula:

In the above formula, the ESS is equal to the error sum squares. xi represents an object and n equal to the number of objects in a cluster. Thus, ESS is obtained from the squared difference of the mean distances from the sum squares of the distance values, and the lower the value, the greater the similarity between the two objects. In summary, the following steps should be made based on the ward method:
-
Each object is considered a cluster.
-
For all possible pairs of clusters, select the two clusters that have less ESS.
-
Combine the two selected clusters.
-
Steps 2 and 3 are repeated until all objects are in a cluster, or the number of clusters has not reached the desired number (23).
To implement and conclude the co-occurrence analysis of words, first requirements including the co-occurrence matrix must be prepared, and then the co-occurrence matrix must be converted into a correlation matrix. To prepare the matrix, keywords with a frequency of 2 were selected and finally, a 98 by 98 square matrix was formed. The diagonal cells of matrices were considered zero, and then the ordinary matrices were converted into a correlation matrix. Finally, the clustering of concepts is plotted on the SPSS statistical software (version 26).
In the next stage a strategic graph of thematic clusters was drawn; to draw the strategic chart, after the formation of discrete matrices for each cluster obtained through the hierarchical graph, the centrality and density of the clusters were achieved using the UCINET software and then strategic chart was drawn. The strategic diagram is the description of internal relationships and correlations between different thematic clusters. In this diagram, the horizontal axis is often used to provide centrality (the degree of correlation of clusters) and from the vertical axis to provide density (the internal communication level of each cluster). Melcer et al. (25) introduce the strategic diagram as an attempt to better illustrate and demonstrate the maturity and coherence of thematic clusters in a research area. The strategic diagram is divided into four sections, each of which forms a quarter of the diagram. The clusters in the first quarter are cohesive and central to the area under study. These major clusters focus on a large portion of the network. The clusters in the second quarter are still cohesive but decentralized, each representing smaller specialized sections of the area under study. In the third quarter, clusters fall; Clusters of this quarter are emerging or declining parts of the network; finally, the fourth quarter contains clusters that are not yet mature but can become the major components (25).
By using the desired search strategy in Web of Science, it was found that 323 related studies were indexed in this database by 1334 researchers from 88 research areas between 1990 and 2021 years. Figure 2 shows the trend of publishing these studies by year.
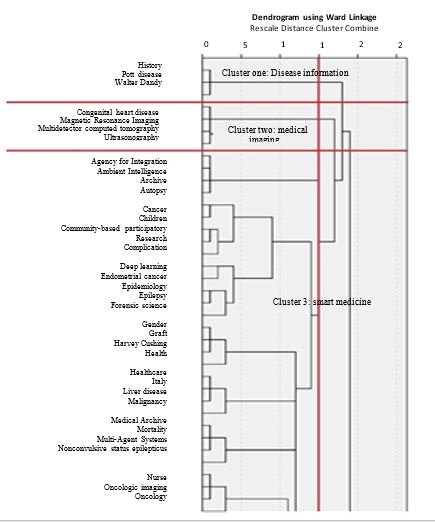


Figure 2. The trend of publishing studies related to medical archives by year
Table 1. Characteristics of research related to medical archives
| Fifth place (number, percent) | Fourth place (number, percent) | Third place (number, percent) | Second place (number, percent) | First place (number, percent) | |
|---|---|---|---|---|---|
| Canada and China (19, 5.9) | Germany (22, 8.6) | Italy (23, 1.7) | England (34, 5.10) | United States (90, 9.27) | Country |
| Abelha A, Hunter I, Iwaya M, Machado J, Pendleton C, Quinones-Hinojosa A (3, 0.9) |
Nakajima T, Ota H, Uehara T (4, 1.6) |
Researcher (number of studies) | |||
| Dougherty AL, Dye JL, Galarneau MR, Holbrook TL, Quinn K (1, 0.3) |
Beddhu S, Bruns FJ, Seddon P, Zeidel ML (2, 0.6) |
Saul M (3, 0.9) |
Researcher (number of citations) | ||
| Hong Kong Polytech Univ, Imperial Coll London, Naval Hlth Res Ctr, Univ Minho, Univ Montreal, Univ Ottawa, Univ Tehran Med Sci, Vanderbilt Univ (3, 0.9) |
Johns Hopkins Univ, Shinshu Univ, Univ Padua (4, 1.2) |
Univ Calif San Diego (5, 1.5) |
Univ Pittsburgh (17, 5.3) |
Institute (number of studies) | |
| Inst Clin Evaluat Sci (1, 0.3) |
EPI SOAR Consulting (1, 0.3) |
Naval Hlth Res Ctr (3, 0.9) |
Univ Ottawa (3, 0.9) |
Univ Pittsburgh (17, 5.3) |
Institution (number of citations) |
| MEDICAL RESEARCH COUNCIL UK MRC, NIH NATIONAL CANCER INSTITUTE NCI, UK RESEARCH INNOVATION UKRI (4,1. 238) |
NATIONAL NATURAL SCIENCE FOUNDATION OF CHINA NSFC (5, 1.548) |
WELLCOME TRUST (9, 2.786) |
NATIONAL INSTITUTES OF HEALTH NIH USA, UNITED STATES DEPARTMENT OF HEALTH HUMAN SERVICES (13, 4.025) |
EUROPEAN COMMISSION (16, 4.954) |
Funding Sponsor |
| CHINESE MEDICAL JOURNAL, EPIDEMIOLOGIA AND PREVENZIONE, IEEE ACCESS, PLOS ONE, SOCIAL HISTORY OF MEDICINE (4, 1.2) |
MILITARY MEDICINE (5, 1.5) |
ARCHIVES OF MEDICAL RESEARCH (7, 2.2) |
MEDICAL HISTORY (11, 3.4) |
Journal | |
| NEUROSCIENCES NEUROLOGY (21, 6.502) |
COMPUTER SCIENCE (22, 6.811) |
PUBLIC ENVIRONMENTAL OCCUPATIONAL HEALTH |
HEALTH CARE SCIENCES SERVICES (28, 8.669) |
GENERAL INTERNAL MEDICINE (41, 12.693) |
Participating research area |
| PSYCHIATRY (270, 6.111) |
PUBLIC ENVIRONMENTAL OCCUPATIONAL HEALTH (278, 6.292) |
NEUROSCIENCES NEUROLOGY (323, 7.311) |
UROLOGY NEPHROLOGY (388, 8.782) |
GENERAL INTERNAL MEDICINE (461, 10.435) |
Citing research area |
| Prevalence (4, 4.14) |
Epidemiology, Population, surgery (10, 4.6) |
Children, risk (12, 5.52) |
Diagnosis, survival (14, 6.45) |
mortality (18, 8.29) |
Key word |
Using SPSS software and calling co-occurrence matrices in this software, hierarchical clustering was performed by the Ward method and a dendrogram diagram (hierarchical clustering) of the topics was plotted. The hierarchical clustering of researches related to medical archives is shown in Figure 3. For greater clarity, the cluster images are divided into sections. It is necessary to explain that first in the hierarchical diagram, each subject is considered as a branch. The most similar elements are then categorized, and these primary categories form small clusters. Eventually, when the similarities diminish, smaller clusters combine to form larger clusters. Of course, in several clusters, some keywords are not semantically related to the content of the cluster. There is usually a probability of occurrence of this issue in co-word analysis because these unrelated keywords are low-frequency keywords that have little effect on the outcome of the cluster compared to the main keywords of the cluster. In this diagram, the height of each cluster indicates where the two clusters are combined; also, the red vertical lines are the index line of interpretation, which is drawn with the opinion of a subject expert (26).
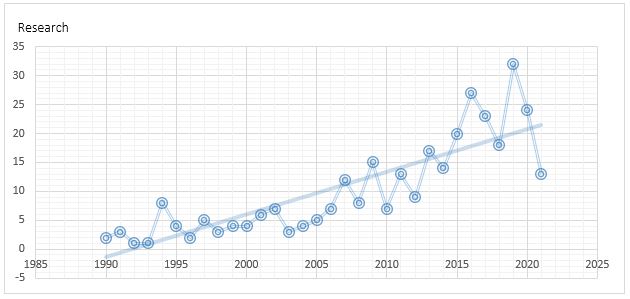
Figure 3. Hierarchical clustering of researches related to medical archives
Cluster 1: Disease information. The results of the co-word analysis showed that cluster 1 was the smallest cluster formed and the three keywords "History, Pott disease and Walter Dandy" were involved in the formation of the first cluster.
Cluster 2: medical imaging. Keywords of this cluster such as "congenital heart disease, Magnetic Resonance Imaging, Multidetector computed tomography and Ultrasonography" show that this cluster can be called medical imaging.
Cluster 3: smart medicine. According to the identification, studying, and review of 68 topics in cluster 3 such as "Ambient Intelligence, Deep Learning, Multi-Agent Systems, ontology, Organizational innovation, etc.", which is also the largest cluster, choosing the smart medical name seems appropriate.
Cluster 4: cancer (oncology and biopsy). The topics of this cluster, which consists of 4 keywords, including "Colon adenocarcinoma, Leucine-rich repeat-containing G-protein-coupled receptor 5, RNA in situ hybridization, and Tumor budding, which generally form a cluster called cancer.
Cluster 5: Pharmacology. This cluster has four keywords "drug metabolism, Parkinson's disease, patient and population health", and based on the keywords, the fifth cluster can be called pharmacology.
Cluster 6: Open data. The existence of keywords such as "Open government, Open government data, Policy, and Records management" caused the sixth cluster should be called "open data".
Cluster 7: types of medical archives. The study of cluster seven indicates that the presence of keywords such as "hospital information systems, medical image and Patient Record" caused this cluster to be named as types of medical archives.
After forming a matrix for each cluster and calling it in UCINET software, the score of centrality and density of clusters was determined and a Strategic graph was drawn using these scores (27). Scores related to cluster density and centrality are shown in Table 2. It should be noted that the origin of the diagram was set at 14 and 1.27, respectively, according to the mean centrality and density of clusters.
| centrality | Density | Cluster title | Cluster number |
| 4 | 1.333 | Cluster 1: Disease Information | 1 |
| 11 | 1.1 | Cluster 2: Medical Imaging | 2 |
| 68 | 1.015 | Cluster 3: Intelligent Medicine | 3 |
| 4 | 1.333 | Cluster 4: Cancer (oncology and biopsy) | 4 |
| 4 | 1.333 | Cluster 5: Pharmacology | 5 |
| 3 | 1.5 | Cluster 6: Open data | 6 |
| 4 | 1.333 | Cluster 7: Types of medical archives | 7 |
Cluster 3 "smart medicine" with a value of 68 has the highest centrality and cluster 6 "open data" with a value of 1.5 has the highest density. This means that cluster 3, which contains the most repetitive keywords, is the most central in terms of influence, relevance to other topics, as well as linking among other keywords. In the strategic graph, the horizontal axis indicates the centrality (the degree of correlation of the clusters) and the vertical axis indicates the density (the degree of internal communication power of each cluster).

Figure 4. Strategic graph of the medical archives field
Due to the thematic diversity in this field and the drawn strategic graph (Figure 4), clusters are present in the second, third, and fourth areas. As the strategic graph shows clusters one, four, five, six and seven are located in the second area. The clusters located in this area are not axially but are developed, although they are at a lower level than the clusters in the first area of the graph. Cluster two, which is located in the third area, is in the lowest rank compared to other clusters in terms of importance and impact in the research area. In other words, the clusters of the third area are emerging or declining because of their centrality and low density, they are marginal topics and have attracted little attention. The third cluster is located in the fourth area of the strategic graph; the clusters in the fourth area are axial but have not yet developed; In other words, this cluster has not yet matured.e apatite family is crystallized by the arrangement of a hexagonal prism with parallelograms. HA also ideally has a hexagonal structure with dimensions of 2 x 30 x 50 nm and has a specific composition of Ca10 (HPO4)6 (OH)2 and a definite crystallographic str-ucture. The chemical
In the last three decades, 323 related studies by 1334 authors affiliated with 548 scientific institutions from 53 countries were retrieved through the WOS database; With 7 related types of research, Iran is the fourteenth among 53 countries participating in research in this field. These studies have also been published in various formats; the highest publication format was for journals (articles, reviews, editorials, and early access) with 91%. However, 9% of the studies are published in other formats (conferences, biographies, news, book reviews, etc.). Data analysis also showed that the predominant language in 88.9 of the studies in this field is English. After English, the most important languages are French (2.8%) and Spanish (2.2%). The United States and Univ Pittsburgh are ranked first in terms of publishing and citation rates. Nakajima T, Ota H, Uehara T has the most scientific production and Saul M have the most citations in researches related to this field. Among the 115 participating research areas, the areas of GENERAL INTERNAL MEDICINE and HEALTH CARE SCIENCES SERVICES had the largest contribution in the researches. On the other hand, the research areas of GENERAL INTERNAL MEDICINE and UROLOGY NEPHROLOGY have the largest contribution among citing researches. The journal MEDICAL HISTORY has published the most researches related to medical archives. EUROPEAN COMMISSION has been the leading research funding sponsor in researches related to this field. In total, the average annual growth rate of the publication of these studies is 34.87%, which indicates a continuous growth situation. The results of this part of the present study are in line with the findings of Hu et al.
Among the topics extracted from researches, the keywords mortality, diagnosis, and survival have gained the most frequency. It seems that information about the number of deaths and causes and factors related to them is one of the most pieces of information needed to diagnose the health status of society and deal with risk factors (28). In other words, examining the common causes of death in a community, in a time and a specific group and comparing it with other communities, periods and groups are one of the important measures that can reduce the risks to planning to improve Health and ultimately help increase the survival of humanity (29). Undoubtedly, by identifying the causes of death on the one hand and by planning and performing the right interventions in life, eating habits, controlling risk factors, etc., on the other hand, we can hope that with proper planning in the future in all dimensions will be prevented the occurrence of many Premature deaths. Also, the diagnosis of medical problems and the reduction of medical errors, which is an important element in the health system and covers various dimensions, including medical imaging, have been among the important topics in researches related to medical archives. Undoubtedly, medical archives with a variety of medical data, information, documents, and records will play an important role in the exchange of medical signs and information, which in turn play an important role in the diagnosis process.
Co word clustering in researches related to medical archives led to the formation of 7 clusters. Among the seven identified clusters, disease information clusters, cancer (oncology and biopsy), pharmacology, open data, and types of medical archives are not central but developed clusters. Medical imaging clusters, on the other hand, are emerging or declining clusters; In other words, the topics of this cluster are marginal and have attracted little attention. At present, the field of medical images and their processing covers a wide range of applications, from the diagnosis of ocular diabetes based on retinal images to the segmentation of MRI images to diagnose human brain tumors (30). The smart medicine cluster is a central but has not yet been developed; in other words, this cluster has not yet matured.
A review of the findings and results of the present study show that the use of medical archives plays an important role in preventing deaths, improving diagnoses and treatments, and ultimately improving the status of all health actors. The use of archives in various processes related to some diseases, including cancer, has also received more attention. The use of archives to record information and history of diseases, as well as drugs, the doses used and the consequences of their use, etc. are other uses of archives in the field of medicine. Addressing the rules and regulations on access to various archives, including medical information and data in the form of open access movement in different governments, has been another topic of researches related to medical archives.
In terms of the top countries in the production and dissemination of research, the results of the present study are in line with the findings of Vaziri (16). Also, the findings of this study are in line with the findings of Sahib (19) in terms of emerging topics, especially in the smart medicine cluster, which includes topics such as deep learning. In terms of published research format, the findings of this study agree with the research of Barrera-Cruz et al. (20). In terms of results, the results of this study conform to the results of the research of Chintalapudi et al. by effective use of medical information and records to diagnose problems and ultimately solve them. The findings of the present study in terms of superior research areas are somewhat in line with the findings of Baji et al.
The analysis of researches related to medical archives leads to a better understanding of currents, discourses and increases the quantity and quality of researches aimed at improving the health system. In other words, the main achievement of co-word analysis of researches related to medical archives by revealing developed topics and identifying thematic gaps in identifying the role and application of medical archives on the one hand and understanding the current situation, improving educational and research policies, management and implementation, and even a balance in the topics of published researches, on the other hand, is useful and therefore will pave the context for the emergence of new research trends. However, in the co-word analysis of words, there are some limitations that, if not taken into account, will make the analysis difficult. For example, the quality of selected keywords is one of the most important steps in the co-word analysis. In the quality of words in the field, the place of its extraction in the document, neglecting the linguistic issues of words, word composition, a semantic relationship of words and the effect of indexing is important and not paying attention to any of these cases will cause poor quality of words analysis. Also, the application of this method in fields that are not prone in terms of words, and concepts is one of the main problems with this analysis, which the lack of attention to which contradicts the conclusion of the research (12). According to the results of the present study, medical archives play an important role in discovering the causes of mortality and subsequently reducing mortality, preventing diseases and their prevalence, improving diagnoses, treatments and ultimately improving the health system. In the present study, "Cluster 3: Smart Medicine" is one of the central but immature clusters. However, the topics of "Cluster 2: Medical Imaging" are emerging topics in the field of medical archives. It is suggested that the results of this study be presented to the relevant organizations and associations.
This article is an independent study that was conducted without organizational financial support.
Conflicts of Interest
The authors declared no conflict of interest.
Received: 2021/05/21 | Accepted: 2021/08/4 | ePublished: 2021/09/5
| Rights and permissions | |
 |
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License. |
Copyright Policy
Iranian Journal of Medical Microbiology by Farname is licensed under CC BY-NC 4.0![]()
![]()
![]()
